


造纸厂需要一种解决方案,能够在纸浆包上的批号被遮挡或受损看不清楚的情况下,仍能识别出纸浆属性。

图1:在运输过程中,印刷到纸浆包侧面的字符内容通常会被遮挡或者模糊不清,因此传统的OCR并不能胜任这些字符的识别。
造纸过程,是从纸浆开始的;纸浆的提供也是一个很长的过程。例如,纸浆很可能产自加拿大或南美,然后再通过轮船、铁路等运输方式运送到世界各地的造纸厂。在运输过程中,特别是在船上,纸浆包经常暴露在恶劣的天气中。
一家业务遍布全球的造纸厂,希望通过优化其生产流程来提高产品质量。在造纸的初期阶段,纸浆包被运输到一个溶解池中。该造纸厂一直未能实现通过印刷在纸浆包上的批号来成功识别每包纸浆,以便将其与系统中的信息匹配,并清楚地检测纸浆成分;但是成功识别每包纸浆,对于实现独立调整生产流程和最终获得最高质量的产品至关重要。
Strelen Control Systems公司管理总监Stephan Strelen解释说,由于纸浆包来自不同的地方,它们的成分会略有不同。“在这种情况下,在任何时候,造纸厂都不能确定溶解池中使用的到底是什么纸浆。溶解是造纸流程的第一步中的一个环节,”他说,“当然你也可以不用了解纸浆的详细成份,但是这样的造纸过程并不理想。对纸浆类型了解越多,就越能把控造纸过程的高质量。”
有时候,纸浆在船运过程中会暴露在风雨中,再通过铁路运输到造纸厂后,纸浆包侧面的文字标识通常已经破损或很难识别,也很难与系统中的信息相匹配。尽管纸浆包上的文字可读性较低,但是造纸厂仍然希望尽可能多地读取这些信息,这将有助于推断纸浆的成分,以及纸浆来自何处,这些信息都有助于优化造纸流程。
造纸厂经常批量使用纸浆包,有时一个批次要使用8包或16包纸浆,而这些纸浆包来自相同的产地。在这种情况下,如果可以读取一个纸浆包上的标识,那么就可以确定这批纸浆的成分和产地。“预计这些代码可能有200或500种变体,”Strelen说。他解释,如果一个纸浆包上的八位数字中的五位数字是可读出的,另一个纸浆包上有四位数字是可读出的,还有一包纸浆上又有五位数字是可读的,“这些信息可能就足够了,因为一旦与数据库进行比较,就会出现一种可能的逻辑组合。”
认识到这一问题后,造纸厂期望Strelen Control Systems公司能提供相应的解决方案。要做的工作是:读取难以读取的批号信息,并与工厂的过程控制单元共享这些信息,从而优化造纸过程,实现更好纸张质量。由于背景不稳定、脏污、打印质量不合格或者因水或撕裂导致的包装损坏等原因,很多时候,印刷在纸浆包上的批号很难看清。纸浆包上的批号无法读取,自然会影响造纸厂的制造过程。过去,制造商会选择OCR方案实现字符的自动化识别,但是在这个案例中,由于字符通常受损严重,传统的OCR方案已不再胜任。
解决方案
Strelen Control Systems公司为造纸厂提供了一套利用深度学习技术的集成系统——Safe Ident OCR。该解决方案包括了硬件和软件部分,封装在防尘、防潮的不锈钢外壳中,非常适合仓库和生产环境。
该方案中采用了多台Basler acA1920-40gm GigE相机,相机配备了Sony IMX249 CMOS传感器,每秒能传输42帧分辨率为2.3MP的图像。这些Basler相机从四个侧面拍摄进入视场的纸浆包,以捕捉纸浆包上的批号信息,并将捕获的信息发送给机器视觉单元。视觉单元检测批号并将其与数据库中的数据相匹配,并最终向生产部门汇报纸浆包的质量信息。
该系统中使用的工业PC是Neousys Technology公司的Nuvo-7000LP系列无风扇计算机,配备Intel第9/8代Core™ i7/i5/i3处理器,6xGbE、MezIO接口和轻薄的机架。机器视觉控制系统使用了西门子的SIMATIC S7-1200 PLC。
Strelen介绍说,除了相机和照明,这套解决方案的核心是MVTec Software的基于深度学习的HALCON OCR软件。借助使用深度学习方法创建的神经网络,可以非常可靠地读取纸浆包上的纯文本。在训练数据的帮助下,即使在背景凹凸不平、印刷质量差、或是字体不常用等很难识别的情况下,这些分类器也可以学习识别纯文本。

图2:MVTec HALCON的Deep OCR功能,具备强大的鲁棒性和扩展的字符识别能力。(图片来源:MVTec Software)
该解决方案利用了HALCON的Deep OCR功能。这是一套全面的基于深度学习的OCR方法,可以局部化字符,而不用考虑其方向、字体类型等特征。自动分组字符的功能可以识别整个单词,这大幅提高了这种方法的识别性能,因为可以避免对外观相似的字符的误解。
HALCON技术产品经理Mario Bohnacker解释说:“HALCON是面向机器视觉应用的一款综合性标准软件。它能服务于所有行业,拥有在广泛的工业领域安装数十万次的软件库。我们的目标是提供一款能适用于多种不同行业、不同应用的软件产品。”
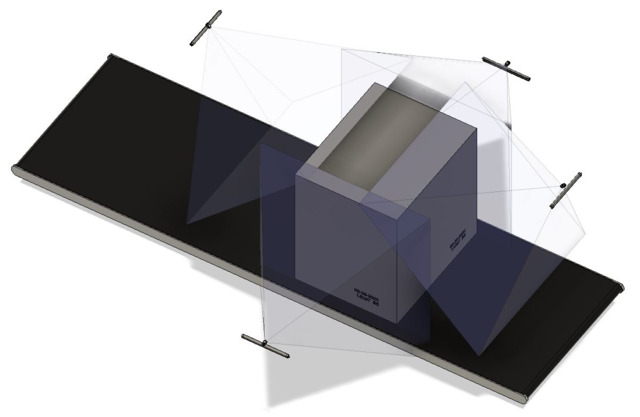
图3:客户端应用示例,四台相机从四个侧面拍摄纸浆包的图像。(图片来源:Strelen Control Systems)
Bohnacker解释说,Strelen Control Systems的Safe-Ident OCR使用了HALCON的Deep OCR功能。“OCR是工业机器视觉领域一个非常典型的应用案例,不同的客户对这种方法都有着大量的需求。实际应用中存在很多非常具有挑战性的字符读取场景。印刷在不同包装或物体上的字符并不总是很清晰。我们的目标是找到一种解决方案,它基本上能够以‘图像输入、字符输出’这样的方式工作。”Bohnacker补充说,“以前的方法,客户必须要选择要读取的字符类型、字符风格(如手写)和不同的字体等选项。相比之下,Deep OCR方案只有一个模型,这意味着只有一个分类器。你只需要输入图像,就可以得到所有字符,而无需考虑字符的方向、大小或风格。”
他继续解释说:“我们提供的是一个深度学习模型,我们使用许多不同印刷风格的图像和高质量图像进行模型训练,从而获得一个模型算法。该算法具有非常强大的识别功能,无论是不同的印刷风格,还是有可能丢掉某些字符的情况,它都能够胜任识别。我们不是用单个字母而是用单词来训练Deep OCR,因此Deep OCR模型可以学习单词的上下文语境,因此它也可以区分单词或数字。”
特殊应用
Strelen表示,这项应用与通常的图像处理和OCR项目有很大不同。通常,我们大多在食品或制药行业使用OCR功能,这两个行业的生产过程非常快,很多食品或药品包装在传送带上移动,不同包装的表面会反射光线,因此必须使用特殊的照明光源。
在造纸应用中,生产过程非常缓慢,因此对硬件的要求并不高。虽然生产过程很慢,但依然处于运动状态,因此相机需要采用全局快门。至于照明,许多OCR应用都需要非常特殊的照明。纸浆包表面反射性不强,因此这项应用只需要提供明亮的照明光即可。因此,这项图像处理方案的关键组件(包括光学镜头、相机和光源)都非常容易部署;这里更重要的可能是所使用的计算机,因为这些造纸厂通常都是24/7的全天候工作模式,因此必须选择性能足够可靠的计算机,以防工作流程的中断。
这项应用的另一个不同之处是,造纸厂不希望拒绝批号标识被损坏的纸浆包。如果能根据其他代码确定批号,这些纸浆包仍然可以使用。
Strelen表示:“公司开始这个项目的时候,Deep OCR尚未出现。我们最初使用的是传统的OCR方案,识别的成功率远低于10%。”当时,Strelen希望该造纸厂去寻求其他解决方案,但这家造纸厂决定继续与Strelen Control Systems公司合作。他补充说,这是Strelen Control Systems公司第一次遭遇识别率如此低的OCR项目,但客户仍然下了订单。在这个项目进行期间,MVTec HALCONs Deep OCR问世了,Strelen Control Systems也将方案由传统的OCR过渡到该技术。部署了新的OCR方案后,纸浆包的识别成功率大大提升,随后该造纸厂又增加了第二条生产线。
(文章转自网络,如有侵权,请联系删除)
















